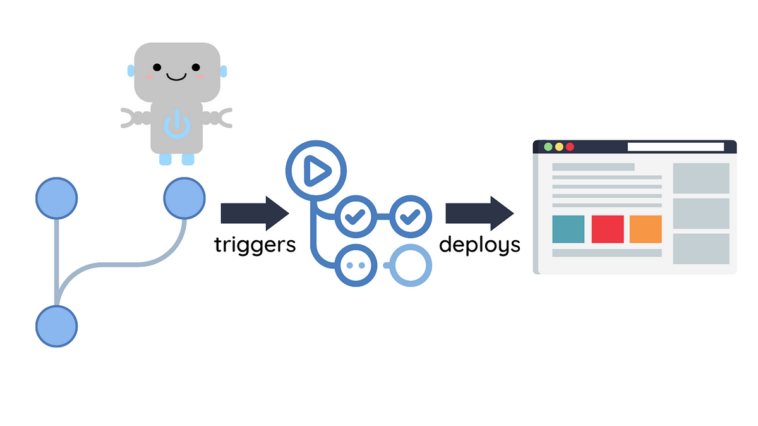
Dans cet article, nous allons parler de la manière de déployer un modèle de machine learning sur un environnement de production à travers une infrastructure de déploiement continue. À travers cette pratique, on peut gagner en temps et augmenter l’efficacité en automatisant le processus de déploiement et en évitant de mobiliser du temps précieux d’un ingénieur pour cette tâche. On propose ici une architecture qui repose sur une intégration continue qui permet, via une série de tests automatisés, de déployer automatiquement tout nouveau modèle ajouté à la branche principale. Après avoir exposé le workflow, on propose une succession d’étapes à suivre pour créer un pipeline de déploiement continu. La méthodologie repose sur l’utilisation d’outils open-source comme MLEM pour enregistrer et déployer le modèle, DVC pour la gestion du modèle et des données, ainsi que Fly.io pour la plateforme de déploiement. La mise en place d’un GitHub workflow est nécessaire pour automatiser tout le processus et garantir l’accès sécurisé aux informations sensibles grâce à des secrets chiffrés. Après avoir suivi toutes les étapes, on peut aisément lancer le nouveau modèle sur l’environnement de production. Cette solution permet ainsi de raccourcir les délais de mise sur le marché et d’améliorer l’efficacité de toute entreprise.
in Loisirs
Automatisation du déploiement de l’apprentissage automatique avec GitHub Actions | par Khuyen Tran | avril 2023
Barbara
1k Views