LES SYSTÈMES DE RECOMMANDATION BASÉS SUR DES GRAPHES
Au cours des dernières années, les systèmes de recommandation sont devenus une partie intégrante de notre vie quotidienne. Ils nous aident à découvrir de nouveaux produits, services et informations qui pourraient nous intéresser en fonction de notre comportement et de nos préférences passées. Cependant, avec la quantité de données disponibles qui ne cesse de croître de manière exponentielle, les systèmes de recommandation traditionnels sont confrontés à plusieurs défis tels que la rareté des données, le démarrage à froid et la scalabilité.
Pour surmonter ces défis, les chercheurs et les praticiens se sont tournés vers les graphes de connaissances, un type de base de données qui organise les données et les connaissances dans un format structuré. Les systèmes de recommandation basés sur des graphes de connaissances exploitent les relations entre les entités et les concepts dans le graphe pour fournir des recommandations plus précises et diversifiées tout en abordant certains des défis mentionnés précédemment.
Dans cette série de Medium, nous explorerons le monde des systèmes de recommandation basés sur des graphes de connaissances et la manière d’aborder les systèmes de recommandation à partir de l’angle des graphes. Nous plongerons dans les concepts de graphes de connaissances et de bases de données de graphes, expliquerons comment représenter les données et les connaissances sous forme de graphes et explorerons divers algorithmes et techniques pour construire et évaluer des systèmes de recommandation basés sur des graphes de connaissances.
Notre objectif est de fournir un guide complet et pratique pour ceux qui souhaitent exploiter les graphes de connaissances pour leurs systèmes de recommandation, qu’ils soient chercheurs, praticiens ou amateurs. À la fin de cette série, vous aurez une compréhension solide des concepts clés et des techniques des systèmes de recommandation basés sur des graphes de connaissances et de leur application dans des scénarios réels.
LES SYSTÈMES DE RECOMMANDATION
Un système de recommandation peut être considéré comme un algorithme permettant de calculer la probabilité qu’un utilisateur (ou un client) souhaite interagir avec un produit ou un service. Ces systèmes ont été initialement introduits pour surmonter le problème de la surcharge d’informations que les clients rencontrent lorsqu’ils sont exposés à un grand catalogue de produits ou de services. En fournissant aux clients des recommandations contextualisées et personnalisées, les systèmes de recommandation visent à réduire la recherche à un ensemble gérable de produits qui sont pertinents pour le client.
Dans la terminologie des systèmes de recommandation, les clients sont appelés utilisateurs et les produits dans le catalogue sont appelés articles. Par conséquent, un système de recommandation peut être considéré comme un moyen de calculer la probabilité qu’un utilisateur souhaite interagir avec un article et d’utiliser cette probabilité pour recommander le sous-ensemble le plus pertinent d’articles à cet utilisateur. Selon le contexte, une interaction correspondrait à l’acte de recherche, d’achat, de visite, de visualisation, etc.
LES SYSTÈMES DE RECOMMANDATION À FILTRAGE COLLABORATIF (FC) ET À BASE DE CONTENU (CB)
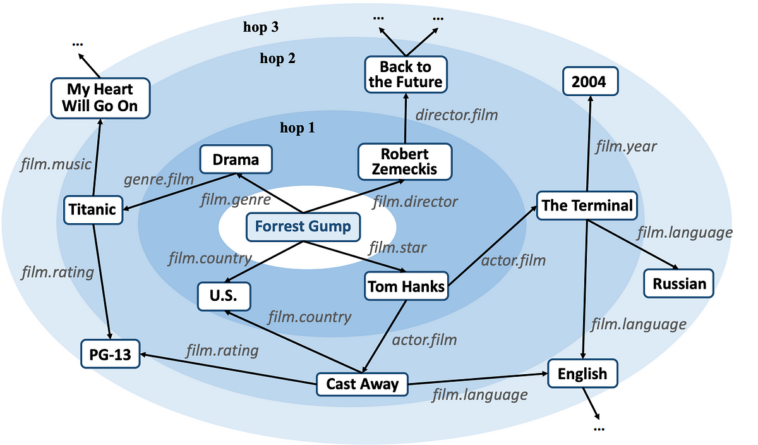
Dans sa forme la plus simple, un système de recommandation est généralement construit en trois étapes consécutives: la collecte d’informations, l’apprentissage et la recommandation. La phase de collecte d’informations consiste à construire un graphe pondéré G = (U, I, E, w), où U, l’ensemble des utilisateurs, et I, l’ensemble des articles, sont les nœuds dans le graphe et E correspond à l’ensemble des arêtes. Ces arêtes représentent les interactions passées entre les utilisateurs et les articles. Il n’y a pas d’arêtes entre les utilisateurs ni entre les articles, donc le graphe est bipartite.
Dans la phase d’apprentissage, un algorithme de machine learning (ML) est utilisé pour entraîner un modèle W qui approxime w dans G. Enfin, dans la phase de recommandation, le modèle entraîné est utilisé pour prédire, pour chaque paire possible (u, i) ∈ (U × I), la force de l’interaction entre l’utilisateur u et l’article i. À partir de ces prédictions, il est alors possible de déduire la liste des articles qui pourraient être recommandés aux utilisateurs.
Les algorithmes CF sont parmi les algorithmes les plus largement utilisés dans le domaine des systèmes de recommandation et ont été appliqués dans des industries telles que le e-commerce ou les divertissements en ligne pour recommander les produits les plus pertinents (par exemple, les films) à leurs clients. Dans la formulation originale, un algorithme FC repose uniquement sur les interactions présentes dans le graphe G sans aucune connaissance ou information supplémentaire sur les articles ou les utilisateurs.
L’algorithme de filtrage CB vise à construire des profils de préférences d’utilisateurs non seulement sur la base d’interactions historiques entre utilisateurs et articles, mais aussi sur une forme de description de ces articles souvent représentée par un ensemble de mots-clés ou de propriétés. Inversement, il est également possible d’associer des articles aux profils d’utilisateurs en regardant la description des utilisateurs qui interagissent avec eux.
En conclusion, les systèmes de recommandation basés sur des graphes offrent des avantages significatifs par rapport aux méthodes traditionnelles en surmontant les défis des systèmes de recommandation classiques. Ces systèmes permettent une recommandation plus précise et diversifiée tout en adressant la rareté des données, le démarrage à froid, et la scalabilité.

