[ad_1]
BOOSTER LA PERFORMANCE DU MODÈLE TRANSFORMER AVEC L’AIDE D’APPRENTISSAGE ACTIF DE L’ÉTIQUETAGE DES DONNÉES
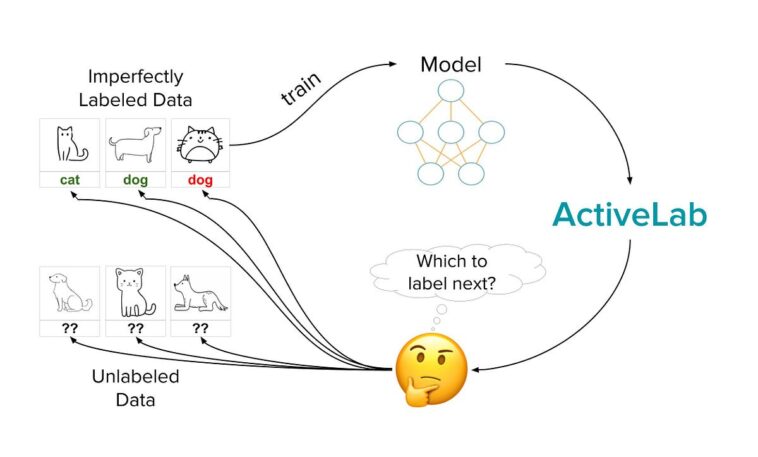
ActiveLab choisit les données pour lesquelles vous devriez (ré) étiqueter pour former un modèle plus efficace. Avec le même budget d’étiquetage, ActiveLab surpasse les autres méthodes de sélection. Dans cet article, nous mettons en lumière l’utilisation de l’apprentissage actif pour améliorer un modèle Transformer affiné pour la classification de texte, tout en conservant le nombre total d’étiquettes collectées par les annotateurs humains à un niveau bas. Lorsque les contraintes de ressources vous empêchent d’acquérir des étiquettes pour l’ensemble de vos données, l’apprentissage actif vise à économiser du temps et de l’argent en sélectionnant pour les annotateurs humains les exemples sur lesquels ils doivent concentrer leurs efforts d’étiquetage.
APPRENTISSAGE ACTIF POUR LA PRIORISATION DE L’ÉTIQUETAGE DE DONNÉES
L’apprentissage actif aide à prioriser les données à étiqueter afin de maximiser la performance d’un modèle d’apprentissage automatique supervisé formé sur les données étiquetées. Ce processus se déroule généralement de manière iterative – à chaque tour, l’apprentissage actif nous indique les exemples pour lesquels nous devons collecter des annotations supplémentaires pour améliorer notre modèle actuel avec un budget d’étiquetage limité. L’apprentissage actif est particulièrement utile pour l’annotation efficace de données dans des environnements où vous avez un grand nombre de données non étiquetées et un budget d’étiquetage limité. Dans ce cas, vous devez décider des exemples à étiqueter pour former un modèle précis. Une hypothèse importante des méthodes présentées ici (et la plupart de l’apprentissage automatique) est que les exemples individuels sont indépendants et identiquement distribués.
ACTIVELAB POUR UN ÉTIQUETAGE EFFICIENT DES DONNÉES
ActiveLab est un algorithme d’apprentissage actif particulièrement utile lorsque les annotateurs sont bruyants car il aide à décider quand nous devons collecter une annotation de plus pour un exemple précédemment annoté (dont l’étiquette semble suspecte) par rapport à un exemple non encore étiqueté. Après avoir collecté ces nouvelles annotations pour un lot de données pour augmenter notre ensemble de formation, nous re-entraînons notre modèle et évaluons sa précision de test.
CROWDLAB POUR LES ÉVALUATIONS MULTI-ANNOTATEURS
CrowdLab est une méthode pour estimer notre confiance dans une étiquette de consensus à partir de données multi-annotateurs, qui produit des estimations précises via un ensemble pondéré de la prédiction probabilistique p_m d’un modèle formé et les étiquettes individuelles attribuées par chaque annotateur j. ActiveLab forme une estimation pondérée similaire, traitant la sélection de chaque annotateur comme une décision probabilistique p_j produite par un autre prédicteur.
OPTIMISATION DE L’ÉTIQUETAGE DES DONNÉES PAR APPRENTISSAGE ACTIF
ActiveLab est le meilleur choix pour les applications d’étiquetage de données dans lesquelles les annotateurs humains sont imparfaits et vous êtes capable de former un modèle de classification raisonnable (qui est capable de fournir des prédictions supérieures au hasard). La méthode fonctionne avec n’importe quelle modalité de données et modèle de classification.
MÉTHODOLOGIE D’ÉTIQUETAGE ACTIF DES DONNÉES
Le reste de l’article présente un exemple concret d’application de l’apprentissage actif pour améliorer un modèle de classification de texte. L’auteur considère une tâche de classification binaire de texte: prédire si une phrase spécifique est polie ou impolie. En comparant la sélection aléatoire des exemples à collecter avec une étiquette supplémentaire, l’apprentissage actif avec ActiveLab produit systématiquement des modèles Transformer bien meilleurs à chaque tour (environ 50% du taux d’erreur), peu importe le budget d’étiquetage total.
TRAINING ET ÉVALUATION DU MODÈLE À L’AIDE DE LA BIBLIOTHÈQUE HUGGING FACE
La première étape de la méthodologie consiste à préparer les données pour l’apprentissage. Les observations étiquetées comprennent un petit ensemble initial de 100 exemples de texte, chacun étant étiqueté avec deux annotations. Les observations non étiquetées comprennent un grand ensemble de 1900 exemples de texte. La variante du Corpus de politesse de Stanford est utilisée comme ensemble de données. Un modèle de Transformer pré-entraîné donne des probabilités de classification des classes pour chaque exemple.
PROCESSUS ITÉRATIF D’APPRENTISSAGE ACTIF ET DE SÉLECTION DE DONNÉES
À chaque tour d’apprentissage actif, des labels de consensus sont calculés pour l’ensemble des exemples étiquetés et non étiquetés. Un modèle de classification est alors entraîné jusqu’à convergence sur l’ensemble d’entraînement ajusté par le consensus des labels et évalué sur l’ensemble de test pour obtenir une estimation de sa performance. Ensuite, des scores d’apprentissage actif sont calculés pour chaque exemple dans l’ensemble d’entraînement et l’ensemble non étiqueté. Les scores les plus bas indiquent les données pour lesquelles la collecte d’une annotation supplémentaire est la plus informative pour notre modèle actuel. À chaque itération, une sélection de n exemples est effectuée, avec n fixé par la taille d’un lot prédéfini.
COMPARAISON ENTRE APPRENTISSAGE ACTIF ET SÉLECTION ALÉATOIRE
Les annotations supplémentaires sont collectées pour le lot sélectionné pour former un nouvel ensemble d’entraînement. L’algorithme est itéré jusqu’à ce que le nombre maximal d’annotations soit atteint. Enfin, des modèles sont comparés entre des approximations de sélection aléatoire et d’apprentissage actif (par comparaison des scores F1). Les résultats montrent que la sélection active est plus performante que la sélection aléatoire, soulignant ainsi l’importance de l’effet de choix des données sur les performances de l’apprentissage automatique.
[ad_2]